Breaking the KV-Cache Memory Wall: A Bare-Metal Trace of Dynamic Eviction Mechanics
Why O(N) transformer scaling fails at runtime, and how Heavy Hitter Oracles reclaim GPU memory by strategically discarding tokens.

Introduction: The Hidden Tax of Autoregressive Generation
When we deploy Large Language Models at scale, we hit a hard physical wall that compute power alone cannot solve: the memory bandwidth bottleneck.
During the decoding phase, an LLM predicts text one token at a time. To prevent redundant O(N) calculations across historical sequences, inference engines allocate an on-chip tensor block known as the Key-Value (KV) cache. While compute intensity stays relatively low during this streaming generation loop, memory load scales linearly with context length.
When your sequence engineering pushes toward extreme lengths, the KV-cache balloons into gigabytes of space. It saturates the GPU memory wires (HBM), leading to severe latency degradation and out-of-memory (OOM) faults. To break through this linear scaling barrier without shedding core model capabilities, state-of-the-art runtimes leverage online attention mapping metrics to selectively drop irrelevant token histories.
To map exactly how these kernel optimizations function under the hood, this post walks through a complete, end-to-end technical workbook trace—covering hardware topology, manual matrix scores, structural state reflections, and zero-dependency PyTorch implementation details.
🛠️ Workshop Materials: Want to run this pen-and-paper hardware trace yourself? Download the empty print-ready PDF template here: [Link to Your Empty Workbook PDF]
Section 1: Core Concepts & Hardware Topology
Advanced inference architectures like H2O (Heavy Hitters Oracle) treat active attention weight maps as real-time metrics for relevance. Empirically, a tiny fraction of tokens (”Heavy Hitters”) continuously absorbs the overwhelming majority of attention score distributions. By maintaining a running total of attention values assigned to each token slot, the serving framework can evict low-contribution items the second capacity thresholds are crossed.
Visual Topology of a Streaming Eviction System
The diagram below maps out how data movements shift within an active, streaming eviction architecture. Note the distinct data paths: active computation registers stream into a fixed-capacity storage array, while a separate tracking and sorting index determines which vector slices hit the compaction line or get dropped entirely to the garbage registers.
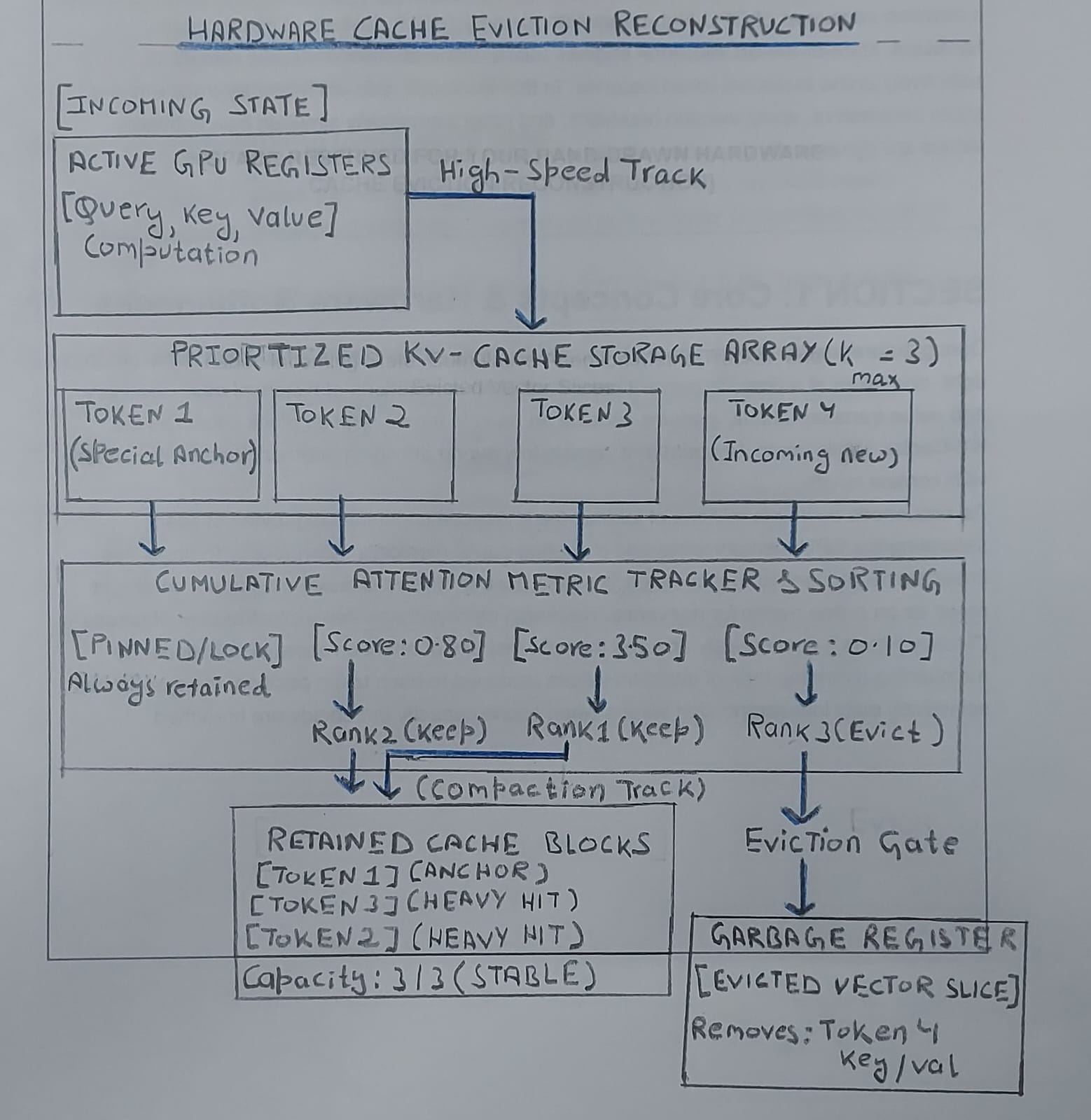
Section 2: The Pen-and-Paper Math Tracker
Let’s simulate the actions of a custom Transformer serving cluster’s bare-metal memory management layer. We will enforce a hard operational constraint where the maximum capacity of our active KV-cache is strictly limited to Kmax = 3 tokens.
The Initial Input State
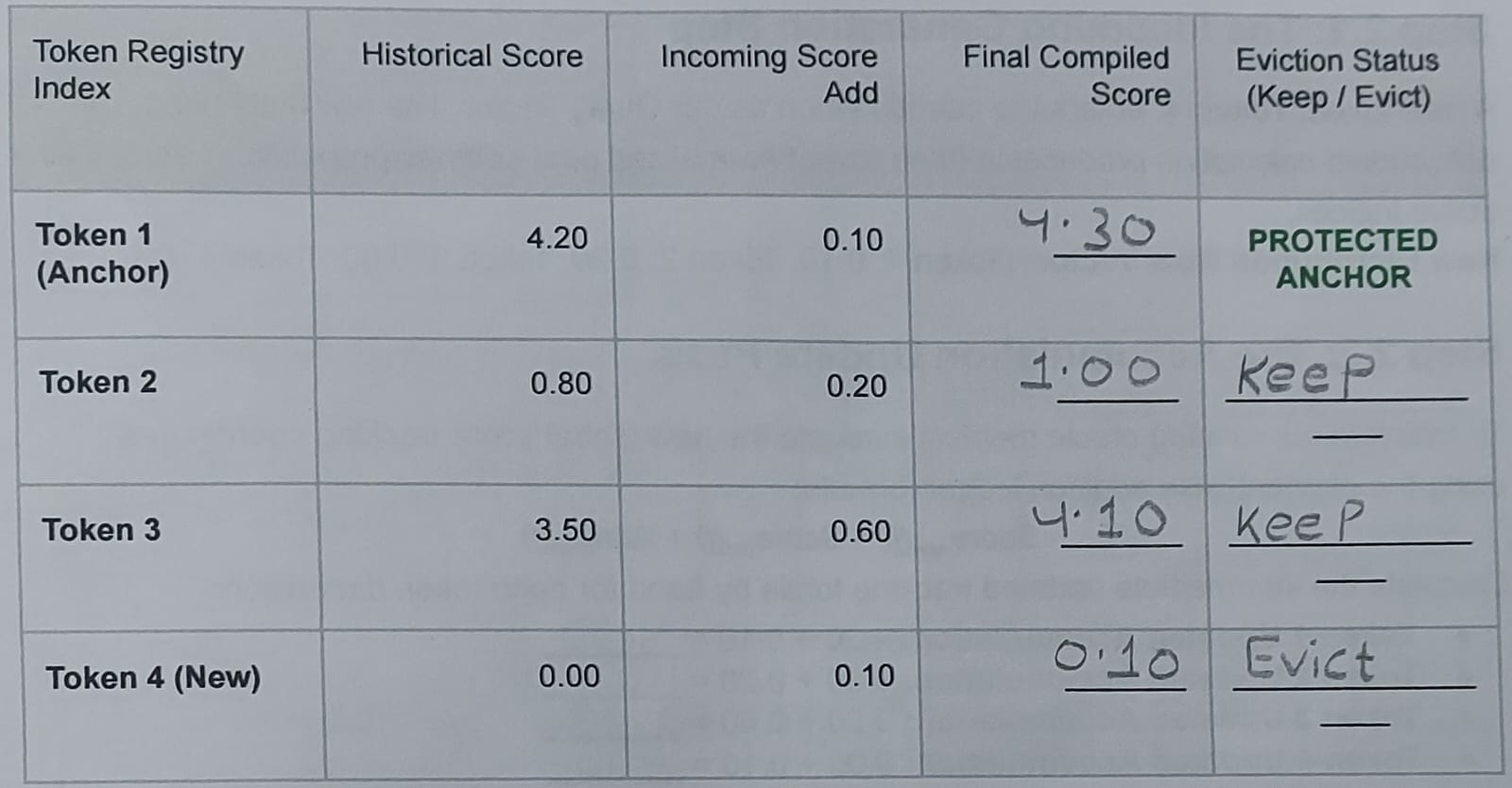
Our memory context begins holding three historical tokens with running cumulative attention weights already compiled into our score tracker ledger:
Token 1 (Special Anchor): Cumulative Attention Score = 4.20
Token 2: Cumulative Attention Score = 0.80
Token 3: Cumulative Attention Score = 3.50
Step 2.1: The Incoming Generation Step
A new token (Token 4) enters the attention loop as our Query vector. The raw multi-head dot-product calculation produces a fresh row of normalized post-softmax probabilities across all active indices:
New Distribution Row Vector:
[Token 1: 0.10, Token 2: 0.20, Token 3: 0.60, Token 4: 0.10]
Step 2.2: The Accumulation Update Pass
To maintain our running oracle metrics without recalculating history, we evaluate global tracking coordinates using element-wise addition:
Token 1: 4.20 + 0.10 = 4.30
Token 2: 0.80 + 0.20 = 1.00
Token 3: 3.50 + 0.60 = 4.10
Token 4: 0.00 + 0.10 = 0.10
Step 2.3: The Heuristic Eviction Filter
Because our updated registry contains 4 entries but Kmax = 3, we execute an eviction pass to protect our hardware boundary limits using standard Heavy Hitter rules:
Anchor Preservation Check: Index 0 (Token 1) represents our structural start-of-sequence token. It is locked in place and cannot be evicted.
Oracle Sorting Track: Sorting the remaining unpinned metrics (Tokens 2, 3, and 4) from highest to lowest score yields:
Token 3 (4.10) —> Token 2 (1.00) —> Token 4 (0.10).
Pruning Operation: We completely clear Token 4 from our memory line since it registers the lowest cumulative attention contribution.
Section 3: Systems & Architectural Reflection
Analyzing these execution states highlights two deep engineering principles regarding why this optimization approach functions so cleanly at runtime:
1. Preventing Semantic Drift via Attention Anchors
In causal language models, early sequence positions (especially the start-of-sequence token) act as dedicated “attention sinks.” Because the softmax operation forces attention distributions across a row to sum to 1.0, layers require a stable baseline token to dump unallocated attention scores into when evaluating text.
If Token 1 is dropped from the cache to save space, subsequent transformer layers lose their baseline alignment point. This causes remaining attention distributions to drastically distort, leading to semantic drift, runaway loops, and hallucinated gibberish. Protecting the anchor preserves global stability.
2. O(1) Metrics via Online Accumulation
Because our oracle metric relies on linear score summation, tracking a token’s structural value over long context lengths does not require reprocessing its raw key and value components from scratch. Since addition is associative and commutative, updating a single floating-point register per token position preserves exact mathematical tracking metrics. This allows us to process the incoming context vector in O(1) tracking updates before slicing out low-value keys and values.
Section 4: Bare-Metal Code Implementation
Below is a zero-dependency PyTorch implementation block demonstrating how online score metrics determine register indexing positions. This script replicates the driver-level tensor slicing actions executed by low-latency serving frameworks.
Python
import torch
def execute_h2o_cache_eviction(k_cache, v_cache, cumulative_scores, latest_attn_weights, k_max=3):
"""
Simulates a heavy-hitter online cache eviction and vector slicing track.
k_cache / v_cache shape: [seq_len, num_heads, head_dim]
"""
# 1. Update the running cumulative tracking registers
cumulative_scores += latest_attn_weights
seq_len = cumulative_scores.size(0)
if seq_len <= k_max:
return k_cache, v_cache, cumulative_scores
# 2. Isolate candidate positions by excluding the anchor token (index 0)
candidate_indices = torch.arange(1, seq_len)
candidate_scores = cumulative_scores[1:]
# 3. Sort candidates to identify the lowest score item
sorted_offsets = torch.argsort(candidate_scores, descending=True)
# Retain the highest heavy hitters + include the index 0 anchor
retained_candidates = candidate_indices[sorted_offsets[:k_max - 1]]
final_keep_indices = torch.cat([torch.tensor([0]), retained_candidates])
final_keep_indices = torch.sort(final_keep_indices).values
# 4. Compact the hardware registers to secure capacity boundaries
k_cache_compact = k_cache[final_keep_indices]
v_cache_compact = v_cache[final_keep_indices]
updated_scores = cumulative_scores[final_keep_indices]
return k_cache_compact, v_cache_compact, updated_scores
Code Execution Debugging Matrix
Question 1: In step 4, what specific functional issue occurs if we change the index allocation assignment from a structured index slicing array to a random selection mask during runtime updates?
Answer: Dropping sequential indexing coordinates breaks structural token order. Because causal transformers use positional embeddings (such as RoPE), scrambling or losing chronological indices means the model will process remaining keys and values in the wrong sequence order. This breaks attention logic entirely and degrades model perplexity.
Question 2: If your context length expands to 10,000 streaming tokens but
k_maxis pinned at 128, how many total tokens will be purged completely from hardware memory lines by the time the sequence loop finishes?Answer: 9,872 tokens. The formula is fixed: Purged Tokens = Total Tokens - Kmax. Over a 10,000-token run, the memory footprints are compressed to hold only the structural anchor plus the top 127 heavy hitters.
Section 5: Hardware Acceleration Notes & Research
Standard transformers spend an estimated 80% of execution cycles bounded by linear memory throughput, stalling while waiting for massive KV-cache historical contexts to clear high-bandwidth main RAM. Keeping key high-contribution metrics pinned within local high-speed SRAM registers bypasses HBM transfer limits entirely. For production clusters, implementing these dynamic eviction strategies yields up to a 5x throughput boost under intensive generation workloads.
Essential Reading for AI Engineers
The H2O Schema: Zhang et al., “H2O: Heavy-Hitters Oracle for Efficient Generative LLM Inference.” arXiv:2306.14048.
FlashAttention Optimizations: Tri Dao et al., “FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.”